


摘要
本文从AI大数据时代处理非结构化数据遇到的问题出发,从而引出向量数据库。向量数据库能够基于向量之间的相似性,快速、精确地定位和检索数据,同时又继承了传统数据库的诸多优势。接着介绍向量数据库Milvus的基本概念与整体架构,重点对Milvus的索引类型与适用场景进行阐述,最后用一个中文语句相似性比较的代码示例来展示Milvus的用法。
向量数据库Milvus简介
一、引言
1.1 非结构化数据的特性与挑战
在当今大数据时代,非结构化数据指的是那些没有预定义的数据模型或不遵循特定格式的数据类型,包括但不限于文本文件、图像、音频、视频等。数据形式复杂,使用传统的关系型数据库管理系统(RDBMS)来存储和查询,会遇到非常大的挑战,具体表现如下:
- 存储成本高:非结构化数据通常体积庞大,如何高效地存储这些数据成为一大难题。同时,考虑到备份和恢复的需求,存储解决方案需要兼顾性能与经济性。
- 缺乏标准化:不同于结构化数据有固定的模式和字段,非结构化数据缺乏统一的标准,增加了数据解析和理解的难度。
- 检索效率低下:由于其复杂的内在结构,从海量非结构化数据中快速找到所需信息变得异常困难。例如,在一个包含数百万张图片的库中搜索相似图像,传统方法往往无法满足实时性的要求。
- 分析复杂度增加:为了从非结构化数据中提取有价值的信息,需要运用先进的算法和技术,比如自然语言处理(NLP)、计算机视觉等,这对计算资源提出了更高的要求。
1.2向量数据库优势
随着人工智能(AI)技术的飞速发展,尤其是深度学习模型的广泛应用,数据处理和分析的需求变得越来越复杂。向量表示能够有效表示语义和捕捉其潜在的语义关系,而向量数据库 应运而生,专门为存储和检索高维向量设计,在机器学习、人工智能等领域发挥着重要作用。向量数据库的核心在于其能够基于向量之间的相似性,快速、精确地定位和检索数据。这类数据库不仅为向量嵌入提供了优化的存储和查询功能,同时也继承了传统数据库的诸多优势,如性能、可扩展性和灵活性,满足了充分利用大规模数据的需求。
- 数据管理:向量数据库提供了易于使用的数据存储功能,如插入、删除和更新操作。通过优化算法(如近似最近邻搜索ANN)可以在海量数据集中快速定位最接近目标向量的数据点,极大地提高了检索效率。
- 元数据存储和筛选:向量数据库能够存储与每个向量条目关联的元数据,用户可以基于这些元数据进行更细粒度的查询,从而提升查询的精确度和灵活性。
- 可扩展性:向量数据库设计旨在应对不断增长的数据量和用户需求,支持分布式和并行处理,并通过无服务器架构优化大规模场景下的成本。
- 实时更新:向量数据库通常支持实时数据更新,允许动态修改数据以确保检索结果的时效性和准确性。
- 备份与恢复:向量数据库具备完善的备份机制,能够处理数据库中所有数据的例行备份操作,确保数据的安全性与持久性。
- 生态系统集成:向量数据库能够与数据处理生态系统中的其他组件(如 ETL 管道中的 Spark、分析工具如 Tableau 和 Segment、可视化platform如 Grafana)轻松集成,从而简化数据管理工作流程。此外,它还能够无缝集成AI相关工具,如 LangChain、LlamaIndex 和 Cohere,进一步增强其应用潜力。
- 数据安全与访问控制:向量数据库通常提供内置的数据安全功能和访问控制机制,以保护敏感信息。通过命名空间实现的多租户管理,允许用户对索引进行完全分区,甚至可以在各自的索引中创建完全隔离的分区,确保数据的安全性和访问的灵活性
二:Milvus简介
2.1 简介
Milvus 由 Zilliz 于 2018 年开始开发,2019 年 11 月在 Apache 2.0 许可证下开源,是世界上首个开源向量数据库1。其最初构想是作为构建和扩展搜索应用的基础设施,旨在成为非结构化数据的搜索工具,后来发展为集搜索、存储和索引于一体的全功能托管数据库1。
2.2 特点
- 高性能向量检索:基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心解决稠密向量相似度检索问题,能对海量数据集进行高效的向量相似度检索,可处理万亿级向量数据索引2。
- 高可用与高可靠:支持在云上扩展,具备容灾能力保证服务高可用。例如 Milvus 2.0 采用存储与计算分离的云原生架构,所有组件无状态,增强了系统弹性和灵活性,目标可用性 / 正常运行时间达 99.9%12。
- 多种索引类型:支持多种索引类型,如 IVF、HNSW 和 DiskANN 等。HNSW 可实现高精度和速度的实时搜索,DiskANN 是面向磁盘优化的索引,能处理超大规模数据,用户可根据不同场景需求选择合适索引3。
- 混合查询能力:支持在向量相似度检索过程中进行标量字段过滤,实现混合查询,满足更复杂的查询需求2。
- 开发者友好:拥有支持多语言、多工具的生态系统,方便开发者集成和使用。能与流行的机器学习框架(如 TensorFlow、PyTorch)和数据科学工具(如 Jupyter)集成6。
- 动态分区与在线更新:支持在线增量数据更新,通过动态分区功能,可按类别或时间等特定条件对数据进行分组,提高查询效率3。
2.3 Milvus基本概念
2.3.1 向量(Vector)
在 Milvus 中,向量通常指的是特征向量(Feature Vector),它是通过各种算法从原始数据(如图像、文本、音频等)中提取出来的数值表示。每个向量代表了一条数据记录的关键特征,可用于计算与其他向量之间的相似度。
2.3.2集合(Collection)
集合是 Milvus 中用于组织和管理向量的基本单元,类似于传统数据库中的表。每个集合可以包含多个分区,并且可以根据不同的业务需求创建多个集合来存储不同类型的数据。
2.3.3 分区(Partition)
分区允许用户在逻辑上将一个集合划分为多个子集,便于更细粒度的数据管理和查询优化。例如,可以根据时间戳或地理位置等因素对数据进行分区存储。
2.3.4 段(Segment)
Milvus 在数据插入时,通过合并数据自动创建的数据文件。一个 collection 可以包含多个 segment。一个 segment 可以包含多个 entity。在搜索中,Milvus 会搜索每个 segment,并返回合并后的结果。
2.3.5 分片(Sharding)
Shard 是指将数据写入操作分散到不同节点上,使 Milvus 能充分利用集群的并行计算能力进行写入。默认情况下,单个 Collection 包含 2 个分片(Shard)。目前 Milvus 采用基于主键哈希的分片方式,未来将支持随机分片、自定义分片等更加灵活的分片方式
2.3.6 索引(Index)
索引是用来加速向量相似度搜索的数据结构。Milvus 支持很多类型的索引(如 IVF_FLAT, IVF_SQ8, HNSW 等),每种索引类型适用于不同场景下的性能优化需求。选择合适的索引对于提高查询效率至关重要。
2.3.7 距离度量(Distance Metrics)
距离度量定义了如何计算两个向量之间的相似度。Milvus 支持多种距离度量标准,包括但不限于欧几里得距离(L2)、内积(IP)、曼哈顿距离(L1)等。不同的应用场景可能需要采用不同的距离度量方式。
2.3.8 近似最近邻搜索(ANN - Approximate Nearest Neighbor Search)
由于精确的最近邻搜索在大规模高维数据集上非常耗时,因此 Milvus 使用了近似最近邻搜索技术来加快搜索速度。尽管结果不是绝对精确的,但能够在可接受的时间范围内找到足够接近的结果。
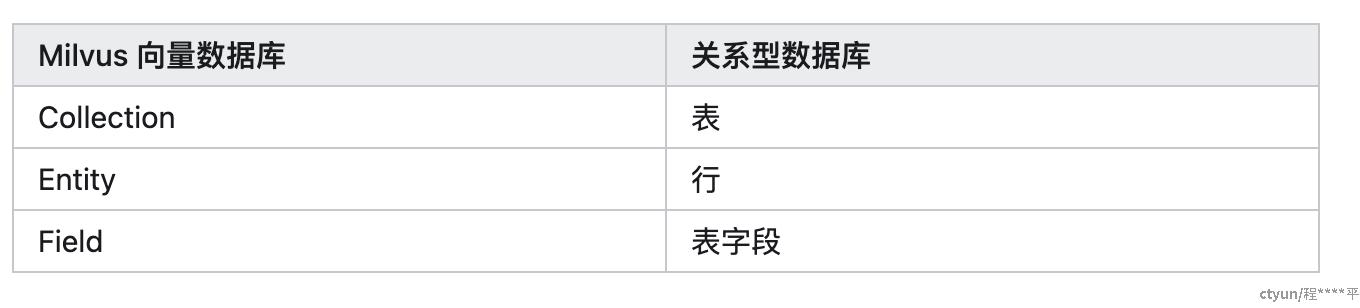
2.3.9 与实体表对比
- Collection-集合包含一组 entity,可以等价于关系型数据库系统(RDBMS)中的表
- Entity 实体包含一组 field。field 与实际对象相对应。field 可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。primary key 是用于指代一个 entity 的唯一值
- Fiedl: Entity 的组成部分。可以是结构化数据,例如数字和字符串,也可以是向量
三:Milvus架构概览
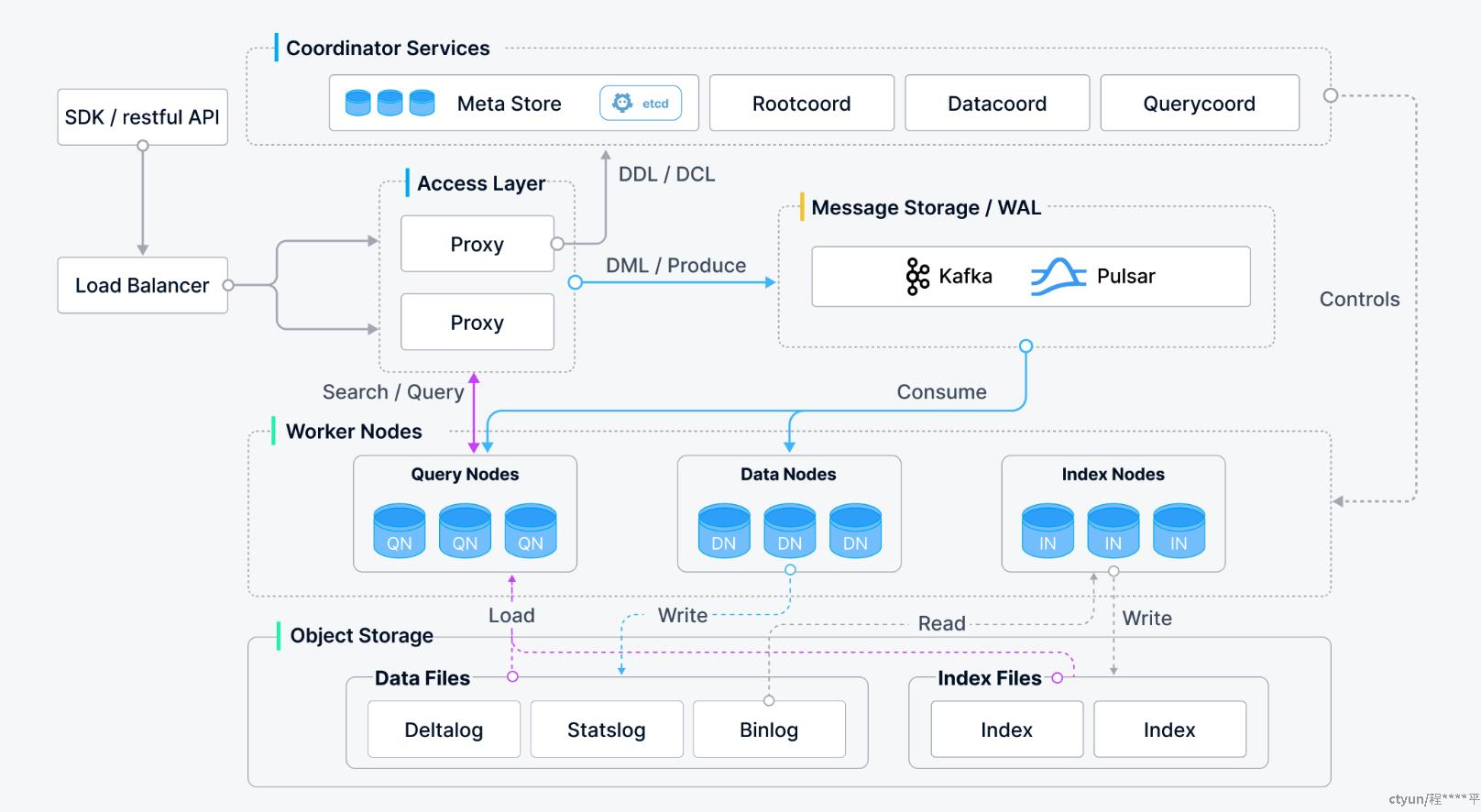
3.1 Milvus 的分层设计
3.1.1 接入层(Access Layer)
- 功能:作为与外部系统交互的第一道接口,主要负责接收客户端请求,并对其进行初步解析和路由。
- Proxy:是接入层的核心组件,它不仅接受来自客户端的请求,还负责负load 均衡、权限验证等前置操作。Proxy 将不同类型的操作(如插入、查询、删除等)转发给相应的内部服务节点执行。
3.1.2协调层(Coordination Layer)
- 功能:协调整个集群中的各种活动,包括元数据管理、任务调度以及状态同步等。
- 组件
- RootCoord:管理集合(Collection)和分区(Partition)的元数据信息,例如集合的创建、删除等操作都需要通过 RootCoord 来完成。
- IndexCoord:负责索引构建任务的分配和监控,确保所有 IndexNode 能够高效地工作。
- QueryCoord:优化查询计划并调度 QueryNode 执行具体的查询任务,以达到最佳性能表现。
3.1.3 计算层(Computation Layer)
- 功能:执行实际的数据处理任务,包括但不限于向量相似度搜索、索引构建等。
- 组件
- QueryNode:专门用于执行查询操作,利用预构建的索引来加速相似度搜索过程。
- IndexNode:负责索引的构建和维护工作。当有新的数据加入或现有数据更新时,IndexNode 会生成对应的索引结构,以便后续查询使用。
3.1.4 存储层(Storage Layer)
- 功能:持久化存储原始数据及索引信息,提供高效的数据访问支持。
- 组件
- DataNode:承担了数据存储的任务,它将从客户端接收到的数据写入磁盘,并在必要时提供给其他组件读取。
- MetaStore:虽然严格意义上不属于存储层,但它负责存储元数据信息,如集合定义、索引配置等,通常基于 RocksDB 实现,保证了高效率的读写性能。
3.2 分层介绍
3.2.1顶层入口:客户端访问入口
- SDK / RESTful API:用户通过 SDK 或 API 发起数据写入(DML)和检索请求。
- Load Balancer:请求首先经过 load 均衡器,分发给后端多个 Proxy 实例。
3.2.2Access Layer(访问层)
- Proxy:
- 负责接收用户请求,并进行初步处理(如数据预处理、合法性校验)。
- 将 DDL/DCL 请求(建库建表)发送给协调器服务;
- 将 DML(插入、查询)请求通过 Kafka/Pulsar 写入 WAL(Write-Ahead Log)。
3.2.3Coordinator Services(协调服务)
- Meta Store:通过 etcd 保存元数据(如集合、字段、分区等信息)。
- RootCoord:管理 DDL 请求(建表、建索引)、写入任务的调度。
- DataCoord:协调数据写入(包括 Segment 的分配、归档)。
- QueryCoord:调度查询任务,协调 QueryNode 的查询执行。
3.2.4Message Storage / WAL(写前日志)
- 使用 Kafka 或 Pulsar 来异步处理数据写入,提高可靠性和吞吐量。
- Proxy 把数据写入后,DataNode 消费消息进行数据持久化。
3.2.5Worker Nodes(工作节点)
3.2.5.1Data Nodes(DN)
- 负责数据写入、Segment 合并、生成 Binlog 等;
- 从消息队列中消费数据,处理后写入 Object Storage。
3.2.5.2 Query Nodes(QN)
- 负责执行向量搜索;
- 支持向量和标量的混合查询;
- 会从 Object Storage load Segment 数据到内存。
3.2.5.3 Index Nodes(IN)
- 负责生成和管理向量索引(如 IVF、HNSW);
- 构建完成后,将索引文件写入 Object Storage。
3.2.6 Object Storage(对象存储)
- 持久化所有数据和索引。
- Data Files 包含:
Deltalog:增量更新Statslog:统计信息Binlog:原始向量数据
- Index Files:
- 存储 Index Node 生成的向量索引。
- Data Files 包含:
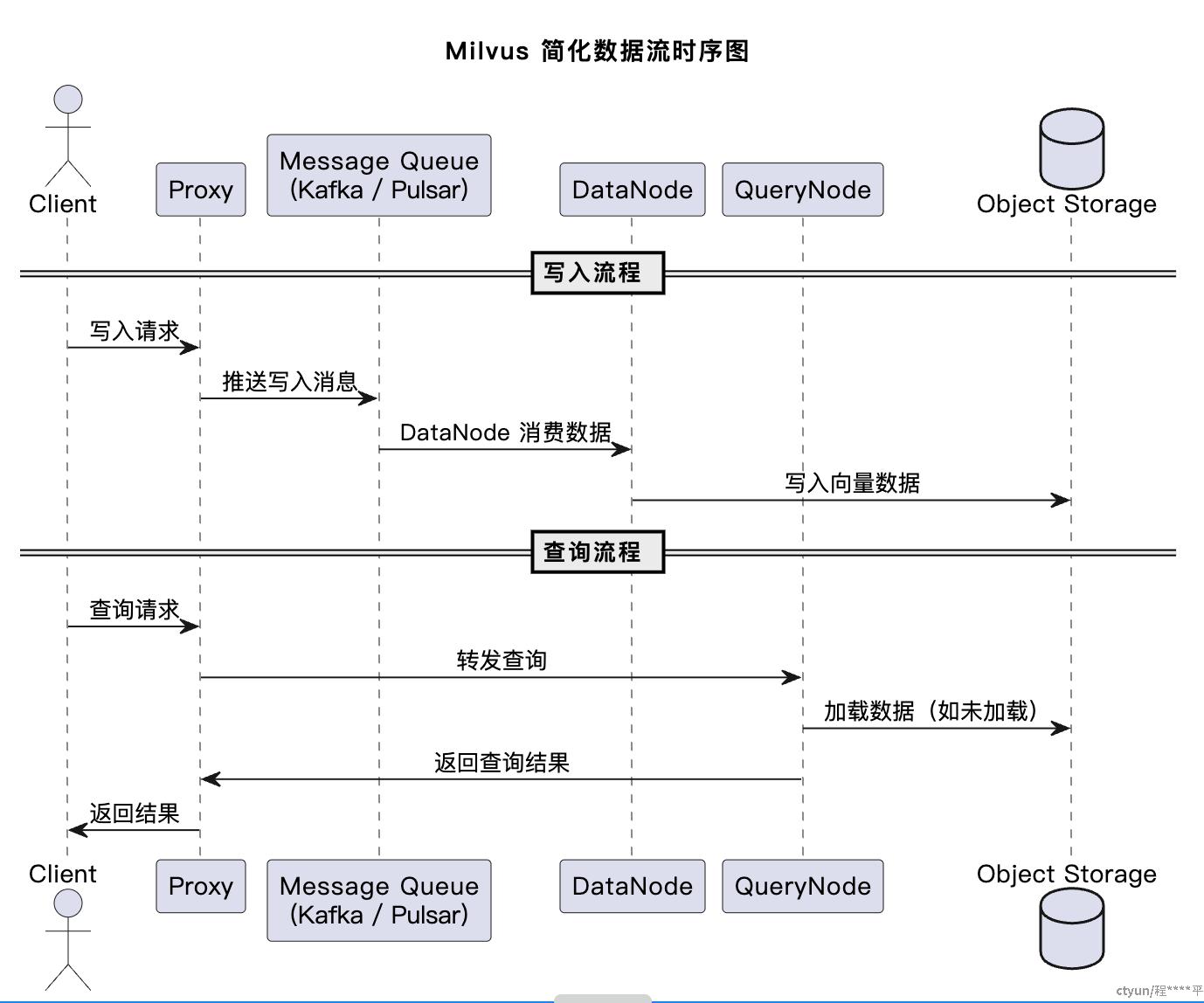
3.3 Milvus 数据流时序图
三:Milvus 索引介绍
3.1 Milvus 索引核心作用
在向量数据库中,索引是提升向量检索效率的核心机制。Milvus 作为高性能向量数据库,通过分层索引架构实现对海量高维向量数据的快速检索,解决传统数据库在处理高维数据时的性能瓶颈问题。其核心目标是:
- 加速相似性查询:通过索引结构减少向量比对次数,提升近邻搜索(ANN, Approximate Nearest Neighbors)效率。
- 支持大规模数据:在百万到百亿级向量数据中实现毫秒级检索响应。
3.2 Milvus 索引类型与技术原理
3.2.1 基于树结构的索引
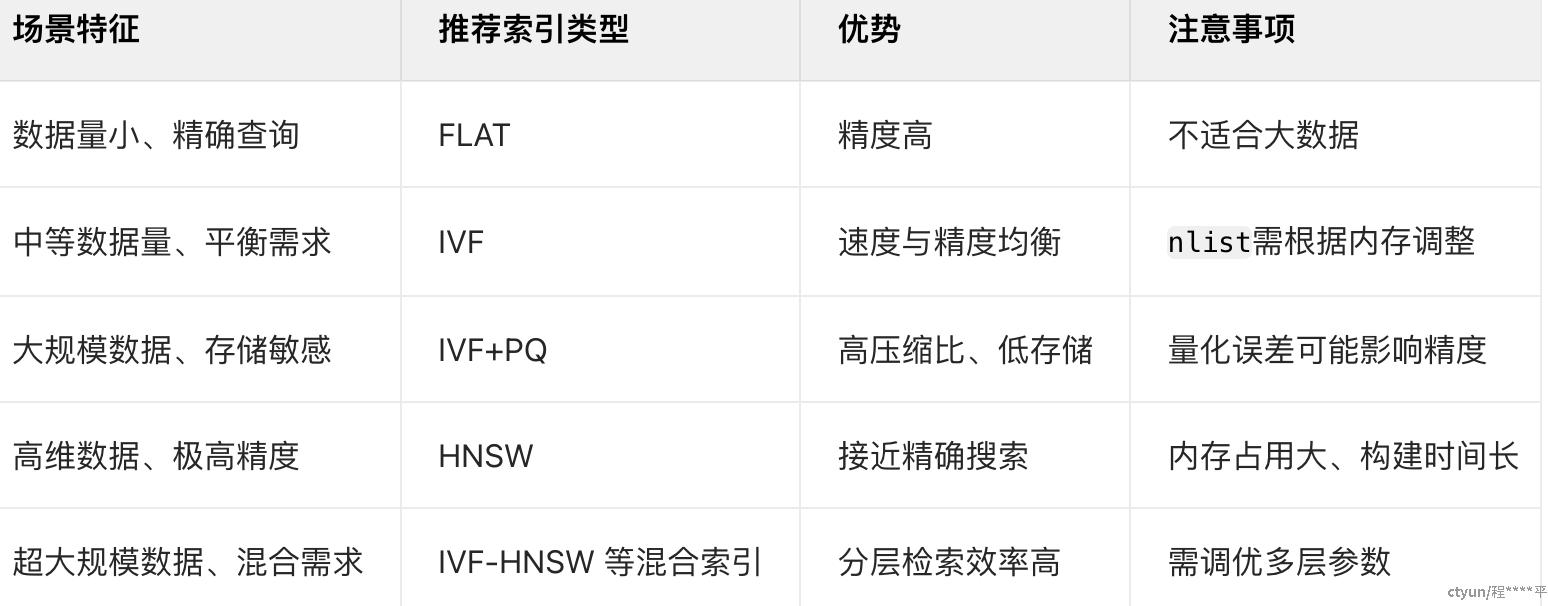
3.2.1.1FLAT(无索引)
- 原理:不构建索引,直接遍历所有向量进行比对。
- 适用场景:数据量小(<10 万)、实时性要求高、需精确查询的场景。
- 特点:查询精度高,但时间复杂度为 (O(N)),数据量大时性能下降显著
3.2.1.2 IVF(Inverted File Index,倒排索引)
- 原理
- 通过聚类算法(如 K-means)将向量划分为多个聚类中心(Centroids);
- 每个向量存储所属聚类中心的索引,查询时仅匹配与目标向量距离最近的若干聚类。
- 参数
nlist:聚类数量,取值范围通常为 (2^4 \sim 2^{20}),越大则检索精度越高但内存占用越大。
- 适用场景:中等数据量(百万级)、需balance 检索速度与精度的场景。
- 特点:时间复杂度降至 (O(N/nlist)),内存占用较低,但牺牲部分精度。
3.2.1.3 IVF + PQ(Product Quantization,乘积量化)
- 原理:在 IVF 基础上,对每个聚类内的向量进行 PQ 压缩编码,将高维向量转换为低维码本,减少存储空间和计算量。
- 参数
m:PQ 分组数,每组单独量化,取值范围通常为 (8 \sim 64);nlist:聚类数量。
- 适用场景:大规模数据(亿级)、需高压缩比和快速检索的场景(如图片 / 视频检索)。
- 特点:存储空间大幅降低(如 128 维向量可压缩至 16 bytes),但存在量化误差。
3.2.2基于图结构的索引
3.2.2.1 HNSW(Hierarchical Navigable Small World Graph,层次化可导航小世界图)
- 原理
- 构建多层级图结构,每层节点通过边连接形成 “小世界网络”;
- 查询时从高层快速定位到低层,逐步逼近目标向量。
- 参数
M:每个节点的连接数,取值范围通常为 (16 \sim 128),越大则图结构越密、精度越高;efConstruction:构建索引时的最近邻搜索范围,影响索引构建速度和质量。
- 适用场景:高维向量(如文本嵌入)、对检索精度要求极高的场景(如推荐系统、语义搜索)。
- 特点:检索精度接近精确搜索,时间复杂度为 (O(\log N)),但内存占用高、索引构建耗时较长。
3.2.3混合索引(Hybrid Index)
- 原理:结合树结构与图结构的优势,例如 IVF-HNSW(先通过 IVF 粗筛聚类,再在聚类内使用 HNSW 细检索)。
- 适用场景:超大规模数据(百亿级)、需兼顾速度与精度的复杂场景。
3.2.4核心决策维度
四:向量数据库实践
4.1 本地 安装
打开本地 Docker Desktop 、从官网download安装脚本并将其保存为 standalone_embed.sh
# 开始
./standalone_embed.sh start
# 停止
./standalone_embed.sh stop
遇到暴露的端口冲突 ,可以在 standalone_embed.sh文件中进行修改
4.2 使用中文向量模型保存与检索向量
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
from sentence_transformers import SentenceTransformer
# pymilvus: Milvus 官方 Python SDK,用来连接、创建集合(Collection)、插入数据、检索等。
# SentenceTransformer: 来自 sentence-transformers,用于将中文文本转为向量。
# 连接 Milvus
connections.connect(host="localhost", port="19530")
# 初始化模型
model = SentenceTransformer("shibing624/text2vec-base-chinese")
# load一个中文句向量模型。
# "shibing624/text2vec-base-chinese" 是一个公开的中文语义编码器,使用 BERT 结构,可以将中文句子编码为 768 维向量。
# SentenceTransformer 封装了 HuggingFace 的 Transformers,用于生成句向量
# Collection 名称
collection_name = "chinese_text"
# 检查并删除旧的 Collection
if utility.has_collection(collection_name):
Collection(name=collection_name).drop()
# 定义 schema 并创建 Collection
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)
]
schema = CollectionSchema(fields, description="中文文本向量测试")
collection = Collection(name=collection_name, schema=schema)
collection.create_index(field_name="embedding", index_params={
"index_type": "IVF_FLAT", "metric_type": "COSINE", "params": {"nlist": 128}
})
collection.load()
# 插入中文数据
texts = ["你好,人工智能的世界", "人工智能正在改变世界", "太阳很大","天气真好", "你喜欢吃什么?", "今天天气晴朗"]
vectors = model.encode(texts, normalize_embeddings=True)
ids = list(range(1, len(texts) + 1))
collection.insert([ids, vectors])
collection.flush()
# 检索:输入一条中文句子进行相似度搜索
query_text = "今天阳光很好"
query_vector = model.encode([query_text], normalize_embeddings=True)
results = collection.search(
data=query_vector,
anns_field="embedding",
param={"metric_type": "COSINE", "params": {"nprobe": 10}},
limit=10,
output_fields=["id"]
)
# 打印结果
for result in results[0]:
print(f"匹配ID: {result.id}, 相似度: {result.distance:.4f}")
匹配ID: 3, 相似度: 0.6905
匹配ID: 6, 相似度: 0.6876
匹配ID: 4, 相似度: 0.6316
匹配ID: 1, 相似度: 0.2981
匹配ID: 5, 相似度: 0.2861
匹配ID: 2, 相似度: 0.2438
四:总结
本文首先聚焦于 AI 时代背景,阐述非结构化数据(如图像、文本、视频等)爆发式增长带来的存储与检索挑战,进而引出核心解决方案 —— 向量数据库。向量数据库的核心优势在于能够基于向量间的相似性计算(如余弦相似度、欧氏距离等),实现海量数据的快速精准检索,为 AI 应用提供底层数据支撑。第二部分围绕向量数据库的典型代表 Milvus 展开,先梳理其发展历程(从 2019 年开源到 2.0 云原生架构的演进),再深入解析其核心概念(向量、集合、分区、段、分片、索引、距离度量)。第三部分结合 Milvus 架构图,分层解析其技术实现。第四部分聚焦 Milvus 的索引体系,详细分类说明各索引的技术原理与适用场景。第五部分从实践出发,通过 Python 代码演示中文语义相似性比较的完整流程(数据准备、Milvus集成、相似性查询)。
Milvus 通过高性能向量检索、云原生架构和丰富的生态集成,成为 AI 时代处理非结构化数据的关键基础设施。无论是初创企业的原型开发,还是大型企业的复杂业务场景,Milvus 都能提供高效、可扩展的向量数据解决方案,推动人工智能应用快速发展。
