


一、拼包与切包的背景
RDMA网卡通过DMA直接从Host内存中拉取数据,绕过CPU和内核协议栈,避免了传统网络通信中多次内存拷贝(如内核缓冲区到用户空间的复制)。这种“零拷贝”机制显著降低了延迟,提升了吞吐量。然而当应用发送的数据分散在内存不同位置时,由于绕过CPU和内核协议栈,因此需要硬件网卡直接聚合非连续内存块,在硬件层面完成报文拼接后发送。
此外,由于RDMA网卡为了避免软件分片和CPU干预,实现微秒级延迟,需要直接将报文数据注入网络,因此还需要硬件网卡根据缓存的pmtu(path mtu)对长报文进行硬件切分。通过动态适配路径特性,在避免后续分片、最大化吞吐,尤其对RDMA、高性能计算等场景具有核心价值。
二、具体实现方案
1. ping-pang RAM方案
拼包切包功能在FPGA中实现的基本结构如下图所示。当数据从host通过dma进入时,硬件只能获取该数据包的长度,而无法获取多个内存区域的数据报总长度;并且pmtu等边带信息与数据包绑定,因而较为简单的思路是创建ping-pang RAM,并使用buffer_ctrl存储报文的边带信息与RAM的控制信息,实现边带与报文的同步。
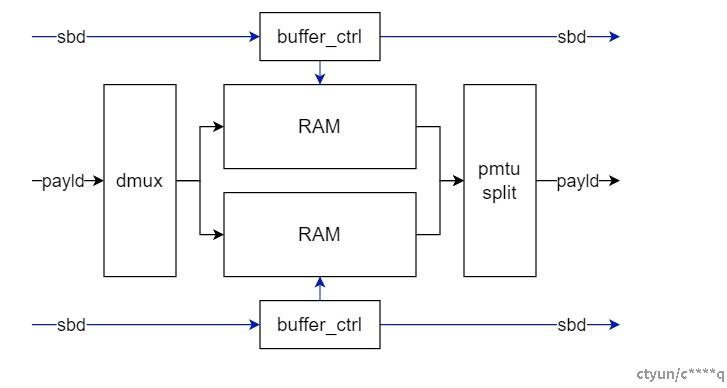
图1. ping-pang RAM方案
Dmux用于将报文根据buffer_ctrl及RAM的状态将数据分配给不同RAM;ping-pang RAM用于拼接并存储报文,相同batch不同包的数据写入同一个RAM中,当相同batch的数据拼接完成并写入RAM后,后续不同batch的数据则写入另一个RAM中,保证buffer_ctrl存储的边带信息始终与各自RAM相对应;pmtu_split用于从特定的RAM中读出存储的数据,并将读出的数据按照pmtu进行拆分后输出。
以上采用ping-pang RAM的方案构思简单,但由于报文长度不固定,且需保证整包缓存,当报文长度较短时会导致RAM利用率不高,造成资源的浪费。
2. 单RAM方案
由于ping-pang RAM方案资源利用率不高,因此考虑将ping-pang RAM合并,RAM合并后的方案二如图2所示。
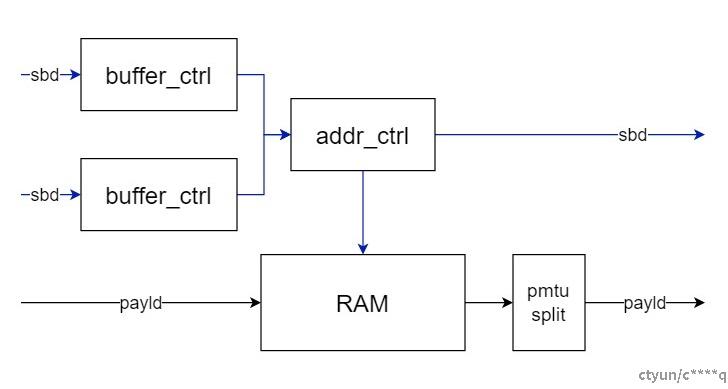
图2. 单RAM方案
将RAM合并后仍可以保留两个buffer_ctrl模块,但需要进一步控制其读写地址,使得RAM的读写地址能够连续。如果单纯地指定buffer_ctrl为前一半或后一半地址,则与方案一相同,所以这里添加addr_ctrl模块,用于记录RAM的切换情况,从而计算当前单RAM的读写地址。单RAM方案继承了ping-pang控制的思想,仍然采用两个读写控制模块,整体思路简单,但实现方式较为复杂,特别是根据不同buffer_ctrl的读写地址进行累加计算出当前RAM的读写地址逻辑,在实际调试中极易出现各种意想不到的情况,给后续维护带来极大的困难。
3. FIFO同步方案
以上两种方案均将sbd边带信息以寄存器方式存储在buffer_ctrl模块,控制payload数据的读写。但以上方案不可避免地会引入各种复杂情况,例如:判断batch是否结束从而判断是否切换buffer_ctrl、判断切换buffer_ctrl后的RAM数据是否已经读出从而确定读写地址等情况。判断条件越复杂,buffer_ctrl模块承载的压力越高,其读写指针等信息在众多条件更新中容易出现错误,导致输出异常。
为了解决以上问题,转换思路。Buffer_ctrl的目的是将边带等控制信息与payload数据同步,从而控制拼包与切包。因此可以将sbd边带信息直接写入进FIFO,避免各种复杂情况下边带信息的变动,并仍然保持与payload数据同步;更进一步,为了避免复杂的读写指针控制逻辑,将存储数据的RAM模块也使用FIFO替换,该方案在FPGA中实现结构如图3所示。
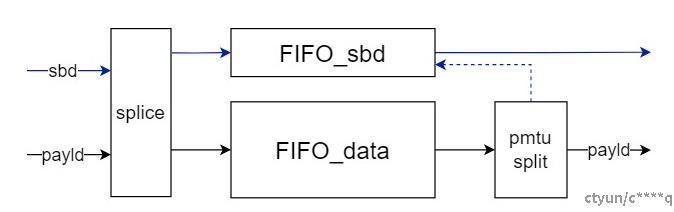
图3. FIFO同步方案
Dma数据输入模块后,首先进入splice模块进行数据拼接,将相同batch不同pkt的empty空间拼接起来,形成一个大包,写入FIFO_data,同时将外部输入的sbd边带信息也写入FIFO_sbd中。考虑到payload data数据量远大于sbd数据量,因此根据pmtu_split切分结果将对应的边带写入FIFO_sbd:每一个输出包对应一个sbd信息。使用FIFO同步data与sbd的方案,尽管新增了FIFO用于存放sbd信息,但大大简化了逻辑复杂度,方便后续维护。同时,后续模块在取数据时,只需要先读FIFO_sbd中的数据,就可以对应地取FIFO_data,简化了后续模块的逻辑。
三、总结
在设计FPGA逻辑时,应尽可能降低逻辑实现的复杂度,虽然ping-pang RAM是较为常见的设计思路,但在流水结构的FPGA实现中可能引入很多较为复杂的控制问题,最终导致难以覆盖全部情况,为后续维护造成不便。而FIFO的控制逻辑简单,能够使边带与数据同步流动,降低了开发和后续运维的难度。
