


1 引言
提出的问题:
- 并不是模型参数量越大模型性能越好,反而小模型在更多训练数据上效果更好(数据量充足的情况下);
- 本文提出的模型训练过程可能耗时,但推理过程非常快
- 本文提出的模型都采用公开的数据集
2 方法
2.1 预训练数据
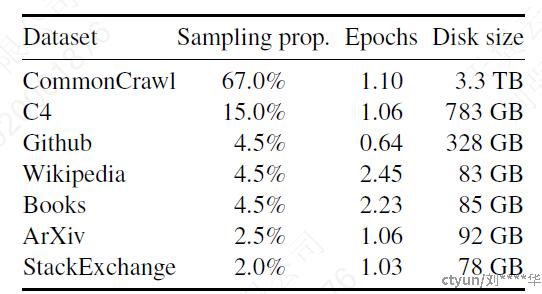
English CommonCrawl、C4
数据集一样,但数据预处理方式不同
Tokenizer
经过tokenization后总共有1.4T个token,每个token在训练过程在只被用一次
2.2 框架
在其他大模型基础上的改进
【GPT3】:对每一个transformer sub-layer的输入进行标准化,而不是输出,标准化函数RMSNorm,目的是提升训练稳定性
【PaLM】:激活函数使用SwiGLU替换ReLU,维度使用 4d替换4d,目的是提升模型性能
【GPTNeo】:使用旋转位置嵌入代替绝对位置嵌入
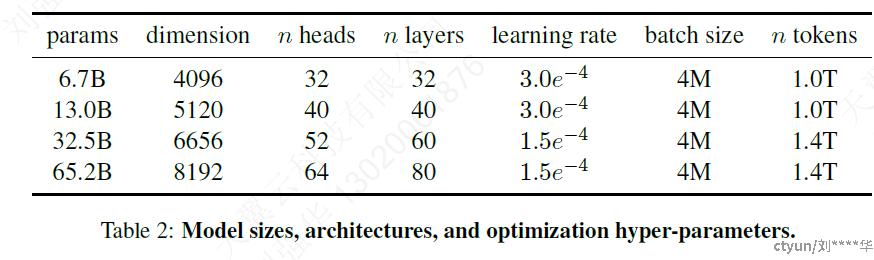
不同超参数如下
2.3 优化器
AdamW optimizer:β1=0.9,β2=0.95,使用cosine学习率,权重衰减(weight decay)为0.1,梯度裁剪(gradient clipping)为1.0,warmup steps=2000
2.4 执行效率
● xformers library:通过不存储注意力权重和不计算由于语言建模任务的因果性质而被mask的key/query分数来实现的
● checkpointing反向传播时减少重复计算的激活数量,通过手动执行transformer层的反向传播,而不是依赖于PyTorch;通过模型和序列冰箱减少内存使用;overlap激活的计算和GPU在网络之间的交流
65B:380 tokens/秒/GPU 2048 A100 GPU+80G RAM
训练包含1.4T tokens的数据集需要21天
3 主要结果
zero-shot任务:提供任务的文本描述和一个测试例子,模型或者直接生成答案或者给备选答案排序
few-shot任务:提供任务的一些例子(1-64)和一个测试例子 ,模型或者直接生成答案或者给备选答案排序
对比的大模型:
非开源:GPT-3,Gopher,Chinchilla,PaLM
开源:OPT,GPT-J,GPTNeo
instruction-tuned:OPT-IML,Flan-PaLM
3.1 常识推理
8个基本的常识推理benchmarks:BoolQ ,PIQA , SIQA ,HellaSwag ,WinoGrande , ARC easy and challenge and OpenBookQA .这些数据集包括完形填空和Winograd风格的任务,以及选择题答案。我们在zero-shot中进行评估。
注:Winograd风格任务用于检测模型是否具备理解语言的能力。该任务由两个句子组成,二者仅有一个单词不同,然后紧接着一个问题。 机器需要识别问题中的前指关系,即指出问题中某一代词的先行词。 为了正确回答问题,机器需要真正理解人类语言,并进行常识推理。
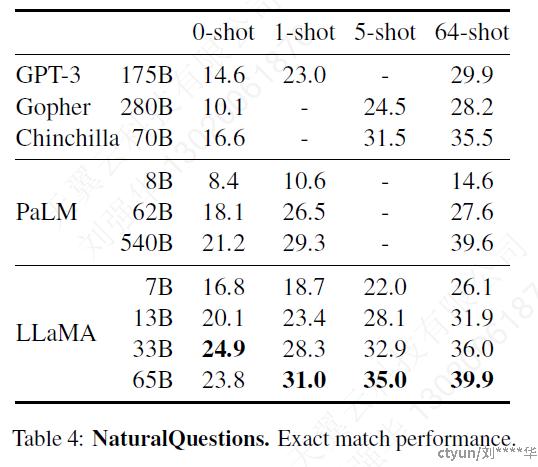
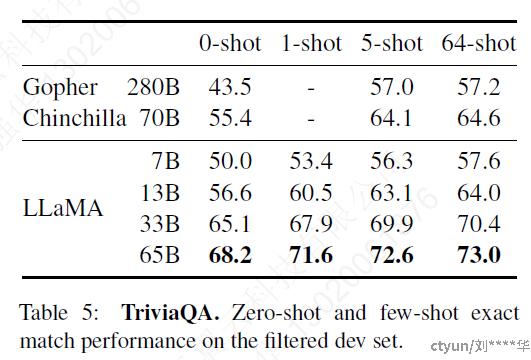
3.2 闭卷问答
两个benchmarks上进行比较:Natural Questions和TriviaQA
计算绝对匹配性能
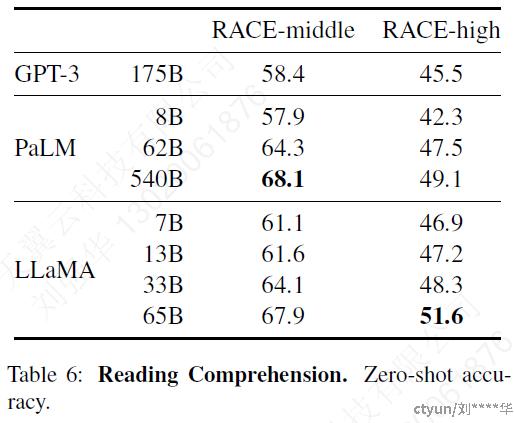
3.3 阅读理解
RACE reading comprehension benchmark:面向中国初高等学校学生
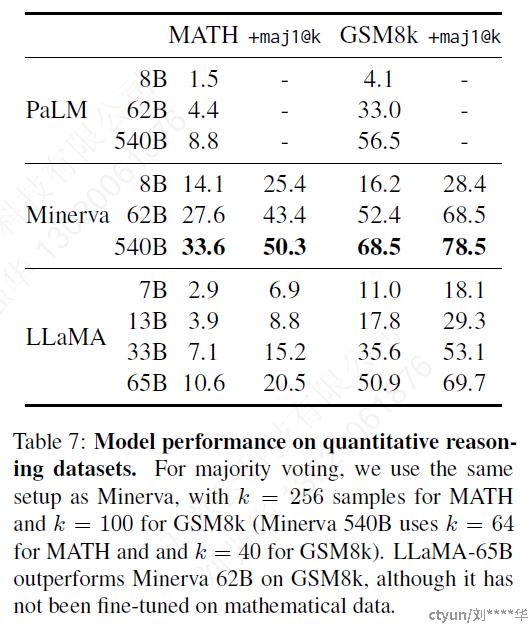
3.4 数学推理
两个benchmarks上进行比较:MATH和GSM8k
与PaLM和Minerva两个模型进行比较,Minerva是将PaLM的一系列模型在数学问题相关的tokens上进行了微调
maj1@k:为每个问题生成k个样本,进行多数投票
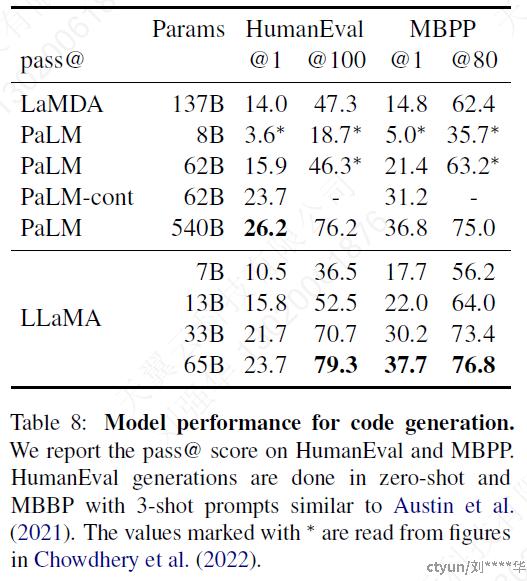
3.5 代码生成
两个benchmarks上进行比较:HumanEval和MBPP
对于这两个任务,模型都接收到用几句话描述的程序,以及一些输入输出示例
HumanEval:接收一个function signature(函数的信息,包括函数名、参数类型、参数个数、顺序以及它所在的类和命名空间),prompt被格式化为带有文本描述的自然代码,在一个docstring(在编程语言(如Python)中,用于描述函数、类或模块功能的字符串。通常位于定义的开头,用三引号括起来)中测试
本文研究的模型都没有在code数据集中进行微调
3.6 大规模多任务语言理解
大规模多任务语言理解基准(MMLU)由多项选择题组成,涵盖了人文科学、STEM和社会科学等各个知识领域。
本文使用benchmarks提供的示例,在few-shot中评估我们的模型
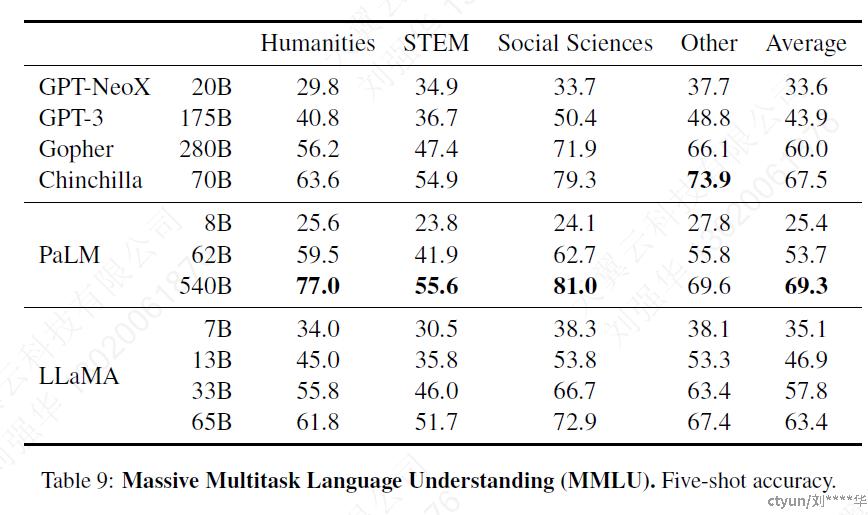
PaLM-540B和Chinchilla-70B效果比较好可能是因为预训练包含的预料更庞大
3.7 训练过程中性能的变化
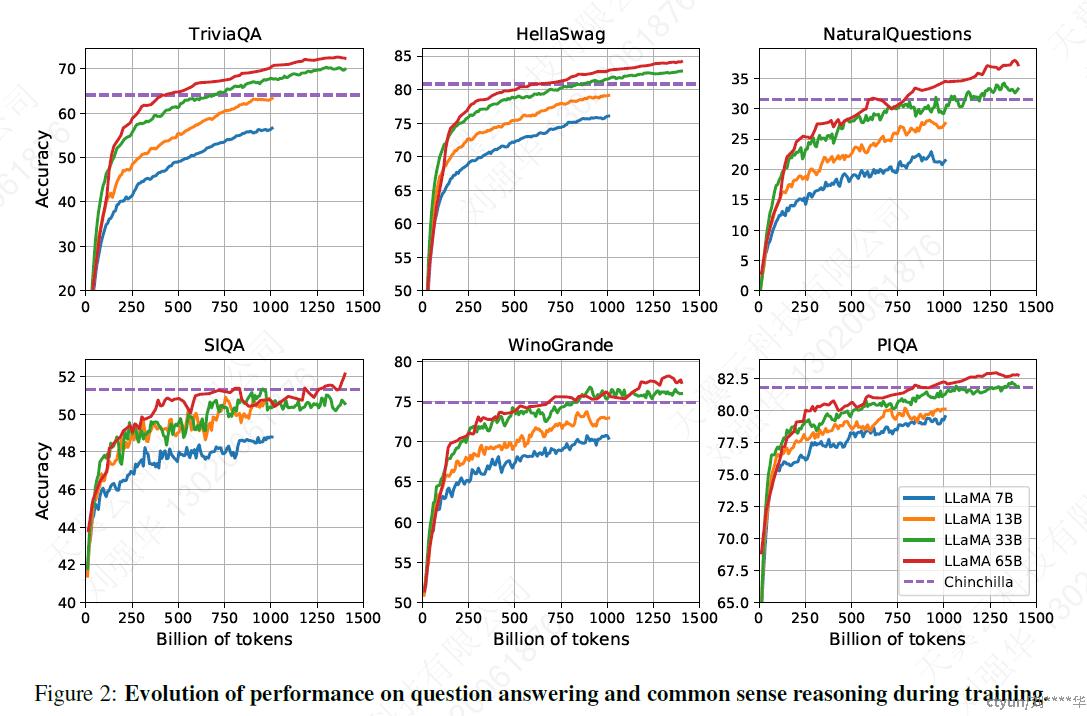
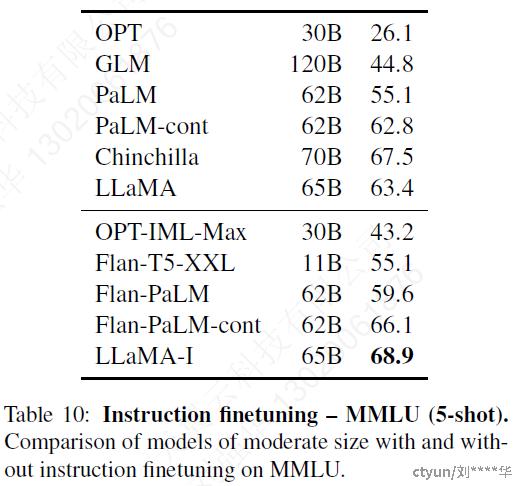
4 Instruction Finetuning
训练一个instruct model LLaMA-I,基于MMLU任务
5 Bias(偏差), Toxicity(攻击性)和Misinformation(错误信息)
大型语言模型已被证明可以再现和放大训练数据中存在的偏差,以及生成有攻击性或令人反感的内容。
5.1 RealToxicityPrompts
RealToxicityPrompts benchmark被作为检测数据集,RealToxicityPrompts由大约10万个模型必须完成的提示组成;然后通过向PerspectiveAPI发出请求来自动评估Toxicity评分。
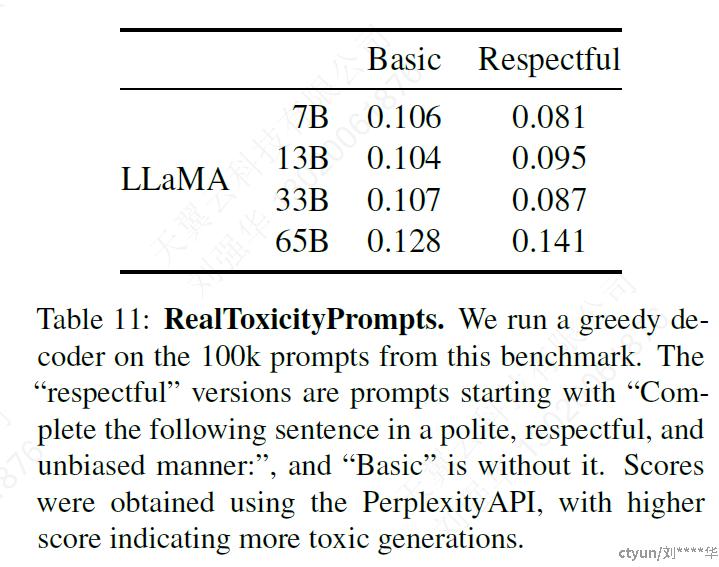
● 随着模型size的增加,模型toxicity也在增加,该规律也可能仅适用于同一家族里的模型
5.2 CrowS-Pairs
使用该数据集进行bias评估,涉及9个方面:gender, religion,race/color, sexual orientation, age, nationality, disability,physical appearance and socioeconomic status。
每个例子都由一个刻板印象和一个反刻板印象组成,在zero-shot设置下使用两个句子的困惑度来衡量模型对刻板印象句子的偏好。
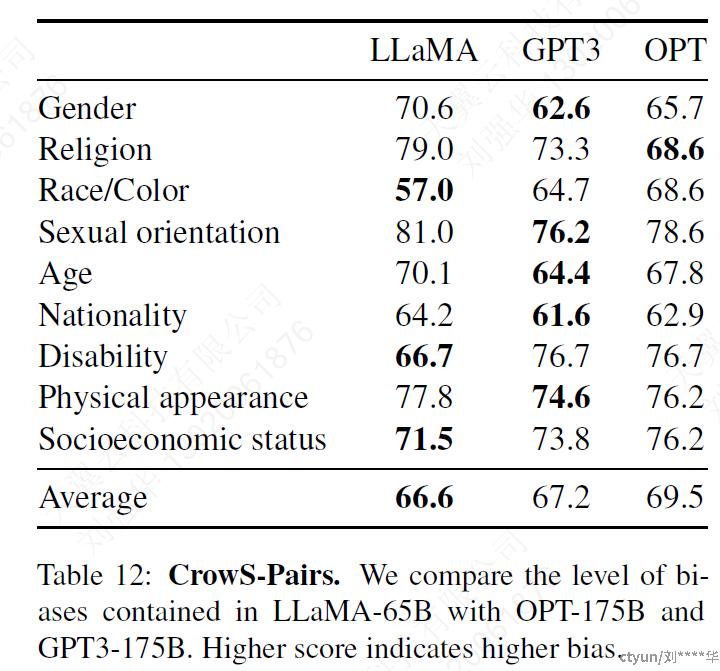
● 可以看到LLaMA的bias相对是比较高的
5.3 WinoGender
该论文为了进一步研究LLaMA在gender上的bias,选择了WinoGender数据集再进行评估
WinoGender是由Winograd模式组成的,通过确定模型的co-reference resolution性能是否受到代词性别的影响来评估偏差。
● 其目的是揭示与职业相关的社会偏见是否已被模型捕获。
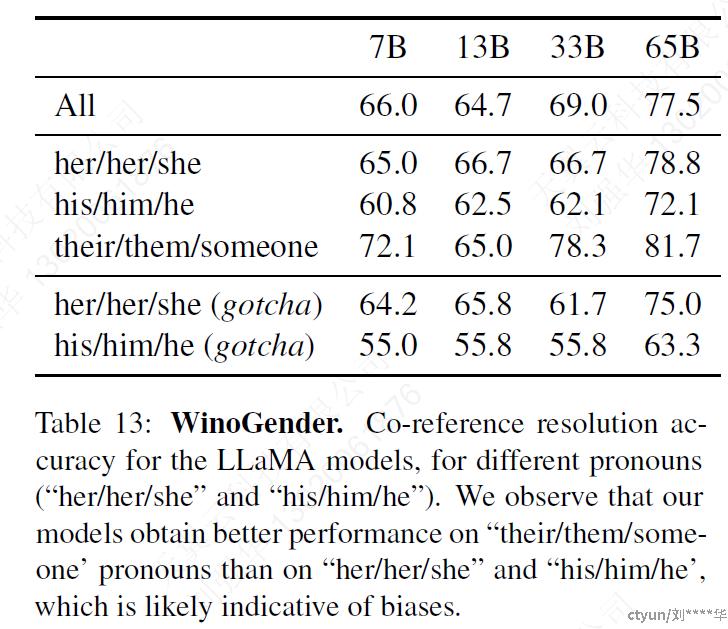
● 上表表示模型在执行“their/them/someone”代词的指代消解方面明显优于“her/her/she”和“his/him/he”代词。在以前的工作中也有类似的观察结果,这可能表明存在性别偏见。
● 在这个案例中
● “她/她/她”和“他/他/他”的代词,模型可能是使用职业的多数性别来执行指代消解,而不是使用句子的证据
● 在表13中,LLaMA-65B在gotcha示例中犯了更多错误,清楚地表明它捕获了与性别和职业相关的社会偏见。““her/her/she”和“his/him/he”代词的表现都有所下降,这是一种不分性别的偏见。
5.4 TruthfulQA
该数据集用于验一个模型的真实性(truthfulQA),即在真实世界中是否正确。这个benchmark可以评估模型产生错误信息或虚假claim的风险。问题的写作风格多样,涵盖38个类别,并被设计成对抗性的。
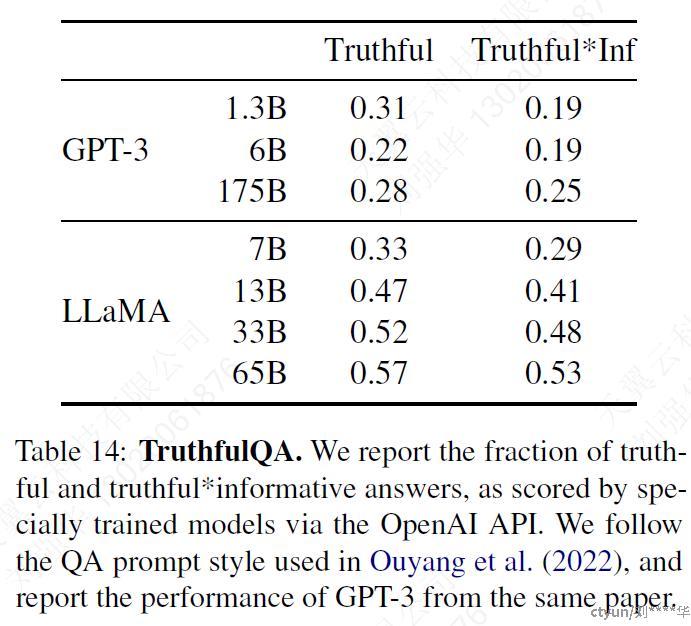
● Truthful(真实):这意味着模型的回答必须基于事实,不能编造或误导用户。在问答系统中,确保回答的真实性是非常重要的,因为它直接影响到用户对系统的信任度和满意度。
● Informative(信息性):这表示模型的回答需要包含有用的信息,能够回答用户的问题或满足用户的需求。一个信息性的回答应该具有实质性的内容,而不是空洞无物或缺乏实质性信息的。
6 Carbon footprint
评估二氧化碳的排放量,使用Watt-hour评估指标。
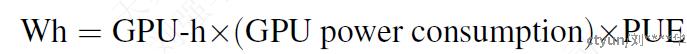
其中Power Usage Effectiveness (PUE)=1.1。由此产生的碳排放量取决于用于训练网络的数据中心的位置。
本文考虑对比模型所用训练数据都存储在相同的数据中心。美国全国平均碳强度因子0.385kg CO2eq/KWh。
大约5个月的时间里使用了2048个A100-80GB来开发论文中的模型。这意味着在以上假设下,开发这些模型将花费约2,638MWh,总排放量为1,015吨二氧化碳当量。
7 相关工作
语言模型
最开始被作为自然语言处理的核心问题,后来被认为是衡量人工智能进步的基准。
架构
n-gram→前向传播/RNN/LSTMs→transformer(self-attention)
规模
模型和数据集规模的变化
BERT、GPT-2、Megatron-LM、T5、GPT-3、Jurassic-1、Megatron-Turing NLG、Gophe、Chinchilla、PaLM、OPT、GLM
8 结论
● 与之前的研究不同,本研究表明,不使用专有数据集,而只使用公开可用的数据集进行训练,可以达到最先进的性能。
● 未来将释放更大规模模型
