1 DeepSeek-LLM:缩放定律
1.1 架构

很大程度上遵循了 LLaMA的设计
- 采用了带有 RMSNorm函数的 Pre-Norm 结构
- 使用 SwiGLU作为前馈网络 (Feed-Forward Network,FFN) 的激活函数,中间层维度为8/3 d_{model}
- 使用Rotary Embedding位置编码
- 67B 模型使用 Grouped-Query Attention (GQA) 代替了传统的 Multi-Head Attention (MHA)
1.2 Scaling Laws 缩放定律
随着计算预算𝐶、模型规模𝑁和数据规模𝐷的增加,模型性能可以得到很大的改善。当模型规模𝑁用模型参数表示,数据规模𝐷用tokens数量表示时,𝐶可以近似为𝐶=6𝑁𝐷。
缩放定律的重要研究目标:在增加计算预算的情况下如何优化模型和数据规模之间的分配。
比如说之前google的一篇论文"Training Compute-Optimal Large Language Models"就指出GPT-3 的训练效果并不是最理想,而更小的模型也能达到同样的质量。
为了确保不同计算预算下的模型都能达到最优性能,首先研究超参数的缩放规律。
1.2.1 超参数的Scaling Laws
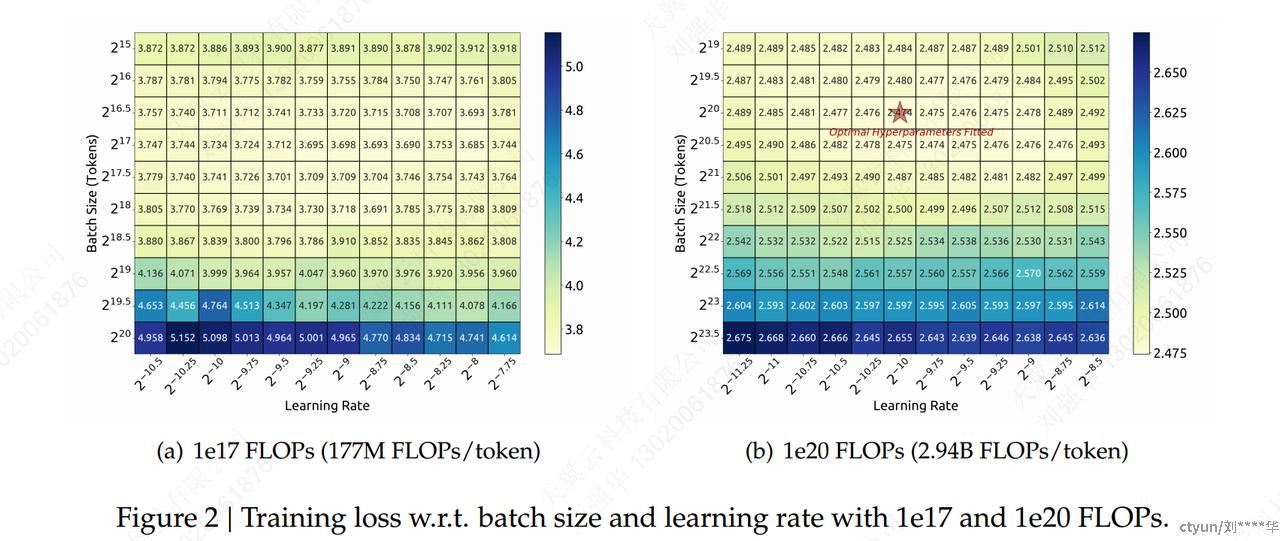
-
在各种batchsize和学习率选择范围内,泛化误差保持稳定。这表明在相对较宽的参数空间(参数取值空间)内可以实现近乎最佳的性能
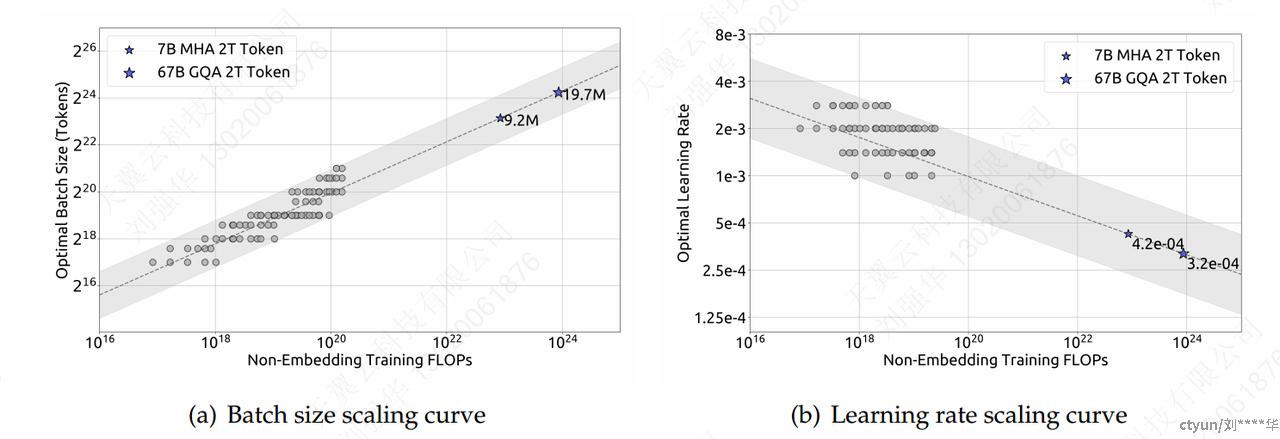
-
随着计算预算 𝐶 的增加,最佳batchsize 𝐵 逐渐增加,而最佳学习率 𝜂 逐渐减小。这符合在扩大模型规模时对批次大小和学习率的直观经验设置
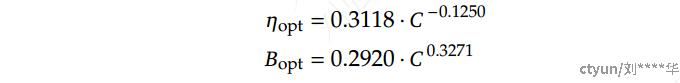
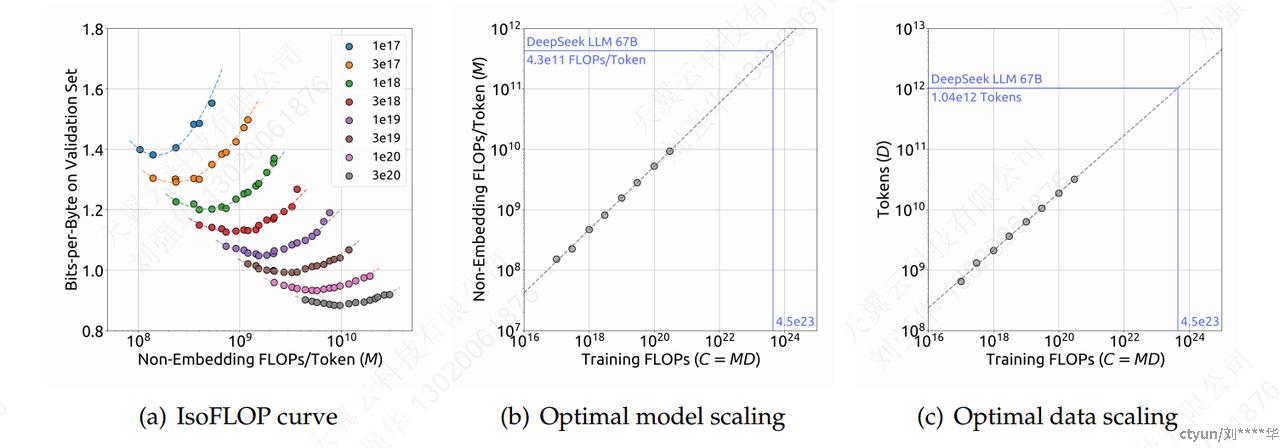
1.2.2 估计最优的模型和数据缩放方式
𝐶=6𝑁𝐷,𝑁不包括注意力的计算开销。
引入非嵌入 FLOPs/token 𝑀,𝑀 包括注意力操作的计算开销,𝐶=𝑀𝐷。
采用𝑀表示模型规模后,目标可以更清晰地描述为:给定一个计算预算𝐶=𝑀𝐷,找到使模型泛化误差最小的最优模型规模M_{opt}和数据规模D_{opt}。这个目标可以形式化为:
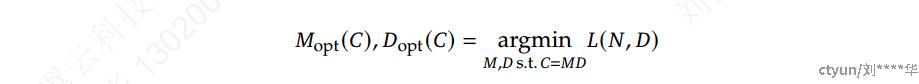
使用 IsoFLOP profile方法来拟合扩展曲线:选择了 8 种不同的计算预算,范围从 1e17 到 3e20,并为每个预算设计了大约 10 种不同的模型/数据规模分配。每个预算的超参数由上述的batchsize和学习率最优公式决定。